Relational Data Analysis
Relational data analysis is a widely used technique based on relational database theory, which puts forward the idea that all data can be held in tables, otherwise known as relations. Relational analysis is about how data can best be organised into relations. For a given dataset, relational analysis will produce a set of tables (or relations) that between them represent all of the data. A relation is equivalent to an entity (see the section on logical data modelling). The illustration below shows two tables that hold information about hospital patients and wards.
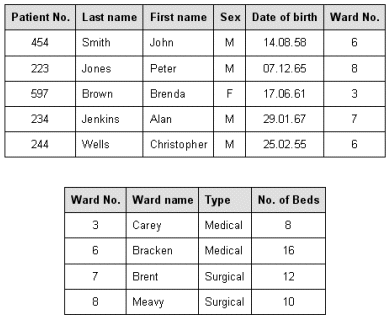
The "Patient" and "Ward" relations represented as tables
A row in the "Patient" table represents a single patient record. Each row must be uniquely identifiable, and there must be no duplicate rows. A combination of all of the attributes in any one row might be required to uniquely identify the row, although in practice it is often only necessary to use one attribute, or at most a small subset of the attributes, for this purpose. The value (or combination of values) used to uniquely identify a row is known as the primary key. For any relation (or table), each primary key must be unique, and a primary key must exist for every row. No significance is attached to the order in which the rows appear.
Each column in the table represents one of the table's attributes, and is given an appropriate heading. For each row and column intersection, only one value can be entered, and the values in a particular column will all have the same data type. As with rows, no significance attaches to the order in which the columns appear. By convention, however, the primary key columns normally occupy the leftmost positions.
The term domain is used to describe the pool of values from which any one column may be drawn. The domain of Patient No. includes all possible patient numbers, not just the ones currently in the hospital. The domain of Sex has only two possible values, male (M) and female (F). The value of domains lies in being able to compare values from different tables that represent the same thing. If we want to find the name of the ward a particular patient is in, for example, we can compare the values of Ward No. in the "Patient" table with the value of Ward No. in the "Ward" table. This only really works if the values being compared come from the same pool of values.
Normalised relations
The object of relational data analysis is to organise all of the data items used by the system into a set of well normalised relations. This means that we eliminate certain undesirable properties, such as unnecessary duplication (redundancy) of data items in different relations, and the possibility of problems arising when we modify, insert or delete data (usually referred to as update anomalies). The term normalisation is sometimes used in place of relational data analysis. Although there have been intensive studies in the past that have uncovered up to fourteen possible levels of normalisation, we are usually only concerned with the first four levels, which are:
- Un-normalised form (UNF)
- First normal form (1NF)
- Second normal form (2NF)
- Third normal form (3NF)
The "normalisation" of data rarely proceeds beyond the third normal form.
In order to carry out the normalisation process, it is necessary to collect enough sample data to ensure that all of the data items involved in the system's processing are listed. To this end it is often a good idea to analyse the documentation used by the various system processes. For our hospital system, for example, we can glean a lot of useful data from the prescription record cards.
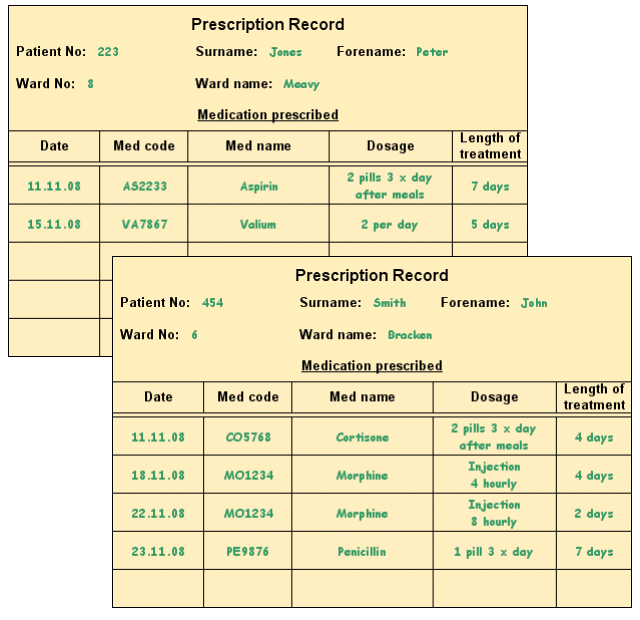
Samples of data are collected from prescription record cards
Un-normalised data
The first thing to do is to tabulate the data in un-normalised form, and choose a suitable key. Column headings are effectively attribute names, and as such should be meaningful but not too long-winded. The key attribute (or attributes) chosen must provide a unique key for the data source. If the key has to consist of more than one attribute (i.e. it is a compound key), use the smallest number of attributes possible. Also avoid using textual keys if practical to do so. For the un-normalised data below, we have chosen Patient Number as the primary key. The value (or values) chosen to be the primary key is underlined to indicate its status.
| Pat No | Surname | Forename | Ward No | Ward Name | Presc Date | Med Code | Med Name | Dosage | Lgth Treat |
|---|---|---|---|---|---|---|---|---|---|
| 454 | Smith | John | 6 | Bracken | 11.11.08 | CO5768 | Cortisone | 2 pills 3 x day after meals | 4 days |
| 18.11.08 | MO1234 | Morphine | Injection 4 hourly | 4 days | |||||
| 22.11.08 | MO1234 | Morphine | Injection 8 hourly | 2 days | |||||
| 23.11.08 | PE9876 | Penicillin | 1 pill 3 x day | 7 days | |||||
| 223 | Jones | Peter | 8 | Meavy | 11.11.08 | AS2233 | Aspirin | 2 pills 3 x day after meals | 7 days |
| 15.11.08 | VA7867 | Valium | 2 per day | 5 days |
First normal form (1NF)
To get the data into first normal form, it is necessary to remove any repeating groups of data to separate relations. You should then choose keys for each new relation identified. A repeating group is a data item or group of data items that occurs with multiple values for a single value of the primary key. In the table above, we can see several values for Presc Date, Med Code, Med Name, Dosage and Lgth Treat. These items are a repeating group and are removed to a separate relation. Note that Pat No is still required to ensure that each row is unique (two patients could conceivably be given the same prescription on the same day). Pat No, Presc Date and Med Code together form the compound primary key for the new relation.
| Pat No | Presc Date | Med Code | Med Name | Dosage | Lgth Treat |
|---|---|---|---|---|---|
| 454 | 11.11.08 | CO5768 | Cortisone | 2 pills 3 x day after meals | 4 days |
| 454 | 18.11.08 | MO1234 | Morphine | Injection 4 hourly | 4 days |
| 454 | 22.11.08 | MO1234 | Morphine | Injection 8 hourly | 2 days |
| 454 | 23.11.08 | PE9876 | Penicillin | 1 pill 3 x day | 7 days |
| 223 | 11.11.08 | AS2233 | Aspirin | 2 pills 3 x day after meals | 7 days |
| 223 | 15.11.08 | VA7867 | Valium | 2 per day | 5 days |
The data is now represented by two tables (or relations) in first normal form. The data items that do not repeat for a single value of the primary key selected for the un-normalised data remain together as a relation, as shown below, and the primary key remains as Pat No.
| Pat No | Surname | Forename | Ward No | Ward Name |
|---|---|---|---|---|
| 454 | Smith | John | 6 | Bracken |
| 223 | Jones | Peter | 8 | Meavy |
Second normal form (2NF)
To get the data into second normal form, we must remove any items that depend on only part of a key to a separate relation. This obviously only applies to relations that have compound keys. We must determine whether any data items in a relation with a compound key are only dependent upon part of the compound key, or upon all of it. In the first of the two relations shown above in first normal form, the combination of Pat No, Presc Date and Med Code together determine the data items Dosage and Lgth Treat, but only Med Code is required to determine Med Name. Thus, Med Name is removed from the relation, and Med Code and Med Name form a new relation, with Med Code as the key. The two second normal form relations thus obtained are shown below.
| Pat No | Presc Date | Med Code | Dosage | Lgth Treat |
|---|---|---|---|---|
| 454 | 11.11.08 | CO5768 | 2 pills 3 x day after meals | 4 days |
| 454 | 18.11.08 | MO1234 | Injection 4 hourly | 4 days |
| 454 | 22.11.08 | MO1234 | Injection 8 hourly | 2 days |
| 454 | 23.11.08 | PE9876 | 1 pill 3 x day | 7 days |
| 223 | 11.11.08 | AS2233 | 2 pills 3 x day after meals | 7 days |
| 223 | 15.11.08 | VA7867 | 2 per day | 5 days |
| Med Code | Med Name |
|---|---|
| CO5768 | Cortisone |
| MO1234 | Morphine |
| PE9876 | Penicillin |
| AS2233 | Aspirin |
| VA7867 | Valium |
Third normal form (3NF)
To get the data into third normal form, we need to remove any data items not directly dependent on the key to separate relations. Here, we are looking for data items that might be dependent on data items other than the primary key. In most cases, these inter-data dependencies are relatively easy to find. Consider the relation below, which we derived when moving from our un-normalised data to the first normal form and which, due to an absence of any part-key dependencies, is already in second normal form.
| Pat No | Surname | Forename | Ward No | Ward Name |
|---|---|---|---|---|
| 454 | Smith | John | 6 | Bracken |
| 223 | Jones | Peter | 8 | Meavy |
We can see a possible a possible inter-data dependency between Ward name and Ward No. Furthermore, although Surname, Forename and Ward No are all dependent on Pat No in this relation, Ward Name does not appear to depend directly on Pat No. This means that Ward Name is determined by Ward No alone, and we can therefore create a new relation from Ward No and Ward Name, in which Ward No is the primary key. Ward No remains in the Patient relation, as its value is determined by Pat No. Here, however, it is acting as a foreign key. A foreign key is a data attribute that appears in a table in which it is not itself acting as the primary key (although it may form part of a compound primary key), whilst at the same time being the primary key in another table. Foreign keys are used to link tables together, as we will see. The complete set of third normal form relations is shown below.
| Pat No | Surname | Forename | Ward No |
|---|---|---|---|
| 454 | Smith | John | 6 |
| 223 | Jones | Peter | 8 |
| Ward No | Ward Name |
|---|---|
| 6 | Bracken |
| 8 | Meavy |
| Pat No | Presc Date | Med Code | Dosage | Lgth Treat |
|---|---|---|---|---|
| 454 | 11.11.08 | CO5768 | 2 pills 3 x day after meals | 4 days |
| 454 | 18.11.08 | MO1234 | Injection 4 hourly | 4 days |
| 454 | 22.11.08 | MO1234 | Injection 8 hourly | 2 days |
| 454 | 23.11.08 | PE9876 | 1 pill 3 x day | 7 days |
| 223 | 11.11.08 | AS2233 | 2 pills 3 x day after meals | 7 days |
| 223 | 15.11.08 | VA7867 | 2 per day | 5 days |
| Med Code | Med Name |
|---|---|
| CO5768 | Cortisone |
| MO1234 | Morphine |
| PE9876 | Penicillin |
| AS2233 | Aspirin |
| VA7867 | Valium |
The Prescription and Drug relations developed when we derived our second normal form relations were already in third normal form, so we now have a complete set of well-normalised relations. We can apply tests to each of our 3NF relations to make sure that they are indeed in third normal form. First, we ask whether, for a given primary key value, there is only one possible value for each of the other data items in the relation. Second, we ask whether each of those data items is directly and wholly dependent on the primary key for the relation. If the answer to these questions is yes, our data is in third normal form. We can now express the relations in SSADM notation, to make them a little easier to interpret:
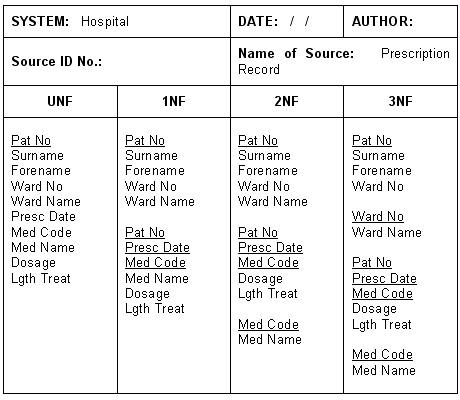
Normalised relations in SSADM notation
Relational data analysis (or normalisation) is usually performed on a number of different data sources and will yield, from each source, a number of normalised relations. The process of combining those relations to form the full set of normalised relations for the information system under investigation is called optimisation. Relations with the same primary key are merged and given a name. The logical data structure that emerges from our analysis will be merged with the "Patient" and "Ward" relations which we examined at the start of this section. The resulting logical data structure is shown below.
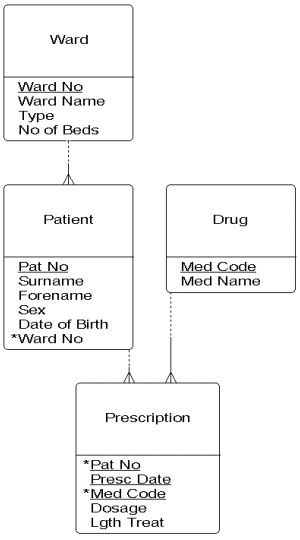
The logical data structure for the hospital system