Uniform Resource Locators
What is a URL?
Before we look at what a URL is, we should probably mention that there is often confusion over the difference between uniform resource locators (URLs) and uniform resource identifiers (URIs). Indeed, there have been more than a few arguments about which of these terms we should be using. The short answer is that it depends on the context in which each of the terms is used.
Unfortunately, knowing what the acronyms stand for doesn't help much in this case. OK, so one is a "locator", and the other is an "identifier". And they both, apparently, refer to some kind of "uniform resource". But what's the actual difference? and why do some people call web addresses "URLs", while others call them "URIs"? And which is correct?
In seeking the "official answer", we have consulted many sources on the subject, including all of the relevant request for comments (RFC) documents published by the Internet Engineering Task Force (IETF). These documents essentially provide the official definitions for all Internet-related terms, and our research suggests that we should call them uniform resource identifiers. In reality, you are more likely to encounter the term uniform resource locator.
The reason for the confusion is that the source documents themselves are dense and poorly written, and at times self-contradictory. For the interested reader, the most up to date of these documents - RFC 3896, published in January 2005 - can be found here. For those who would just like a simple explanation of what the terms mean . . . well, we'll do our very best.
RFC 3986 describes the uniform resource identifier (URI) as "a compact sequence of characters that identifies an abstract or physical resource". The introduction goes on to say that a URI "provides a simple and extensible means for identifying a resource". So far so good. We even get an explanation (of sorts) of what the individual terms mean. The word uniform is used, for example, because:
"Uniformity . . . allows different types of resource identifiers to be used in the same context, even when the mechanisms used to access those resources may differ. It allows uniform semantic interpretation of common syntactic conventions across different types of resource identifiers. It allows introduction of new types of resource identifiers without interfering with the way that existing identifiers are used. It allows the identifiers to be reused in many different contexts, thus permitting new applications or protocols to leverage a pre-existing, large, and widely used set of resource identifiers."
And that is just the beginning. Don't be too upset if you don't feel particularly enlightened. Even if you read it several times it doesn't tell you very much. But at least the terms "resource" and "identifier" are fairly self-explanatory. A resource can be a physical resource such as an internet server, or an abstract resource such as a file or a network service portal. An identifier is the name we use to identify a particular resource.
But what is the difference between a uniform resource identifier and a uniform resource locator, and does it actually matter? To answer the second part of the question first, the majority of people use the term uniform resource locator (or just URL) even if what they are talking about should, strictly speaking, be referred to as a uniform resource identifier. We have never encountered a situation where this has led to any misunderstandings.
Nevertheless, it is useful to be aware of the difference, even if only for the feeling of smug superiority you may briefly get whilst explaining the whole thing to those less well-informed. So, let's start with uniform resource identifiers. They identify a resource (for the purposes of this discussion we're not going to worry about the implications of the word "uniform"). According to section 1.1.3. of RFC 3986:
"A URI can be further classified as a locator, a name, or both."
If we read a little further, we come across the following in section 1.2.2.:
"A common misunderstanding of URIs is that they are only used to refer to accessible resources. The URI itself only provides identification; access to the resource is neither guaranteed nor implied by the presence of a URI."
So essentially, we are safe to assume that a URI is guaranteed to identify a resource. It is not guaranteed to tell us where that resource is, or how to access it (but it might). However, section 3.1., which provides a definition of the term "scheme", says that:
"Each URI begins with a scheme name that refers to a specification for assigning identifiers within that scheme."
The term "scheme", as we shall see in due course, is frequently used to identify the protocol used to access a resource. The complete internet address of a web page, for example, will utilise either the http or the https scheme. This implies that the URI does in fact tell us how to access the resource it identifies.
However, not all schemes are associated with resources that have a specific location. One of the example URIs given in RFC 3986 is a telephone number:
tel:+1-816-555-1212
The scheme in this instance is tel, which informs us that we are looking at a telephone number (as opposed, for example, to a social security number). So, the URI is identifying the resource, but it doesn't give us any location information.
Let's turn now to the uniform resource locator (URL). The first thing we should say is that prior to the publication of RFC 3986 in 2005, it appears to have been perfectly acceptable to use the acronym "URL" when referring to the address of an Internet resource. We base this conclusion on the fact that the preamble to RFC 3986 clearly states that it updates RFC 1738, a request for comments published in December 1994 and entitled "Uniform Resource Locators (URL)". The introduction to RFC 1738 states:
"This document describes the syntax and semantics for a compact string representation for a resource available via the Internet. These strings are called 'Uniform Resource Locators' (URLs). The specification is derived from concepts introduced by the World-Wide Web global information initiative, whose use of such objects dates from 1990 and is described in "Universal Resource Identifiers in WWW", RFC 1630."
We can extract a few essential points from this. A uniform resource locator is a string representation. It refers to a resource that is available on the Internet. And, by implication, it is also a uniform resource identifier. RFC 1738 goes on to say, under the heading General URL Syntax, that:
"URLs are used to 'locate' resources, by providing an abstract identification of the resource location."
In other words, it's an address of some kind for an Internet resource of some kind. The subtle difference between URLs and URIs is that a URL will identify some resource on the Internet and tell you how to get to it. A URI will also identify some resource on the Internet and might tell you how to get to it, but does not guarantee to do so. In fact, there is no guarantee that the resource identified by a URI even exists.
The bottom line is that all URLs are URIs, but not all URIs are URLs. From one perspective, we can perhaps understand why the IETF insists on the use of the more generic term URI. On the other hand, web developers tend to be interested only in Internet resources they can actually access and use, which of course necessitates the use of a URL.
All URLs are URIs. but not all URIs are URLs
Furthermore, the URL acronym is now so entrenched in the vernacular of the web that to abandon it in favour of URI could well be counter-productive. Everybody involved in web development - and these days, just about everybody who uses the Internet - knows exactly what a URL is, even if they don't actually know what the acronym stands for. Our advice in this respect is to go with the flow. If someone insists on calling a URL a URI (or vice versa) there is little to be gained from being pedantic.
The anatomy of a URL
From this point forward we will be concentrating on uniform resource locators (URLs) which, by definition, are also uniform resource identifiers (URIs), because we are primarily interested in accessing web resources that exist somewhere on an Internet server. In the majority of cases, the resources we want to access are things like HTML documents, cascading style sheets, JavaScript files, image files, and various kinds of media file.
Most of the resources we require will be accessed using the hypertext transfer protocol (HTTP), but we may on occasion use other protocols, such as file transfer protocol (FTP), and email. The first part of a URL thus identifies the protocol that will be used to retrieve or access the resource.
According to RFC 1738, in which the uniform resource locator was originally defined, the first part of every URL, which identifies the protocol to be used, is called the scheme. Everything that follows the scheme is called the scheme-specific-part, and its interpretation is dependent on the scheme. The general syntax of a URL given by RFC 1738 is as follows:
<scheme>:<scheme-specific-part>
The scheme-specific-part will typically include a hostname and other information required to access the resource, such as a filename, and the path to the file. Bearing in mind that a URL is essentially a specific kind of URI, we will from this point onwards use the description given in RFC 3986 to refer to a URL's syntax components:
"The generic URI syntax consists of a hierarchical sequence of components referred to as the scheme, authority, path, query, and fragment."
We'll deal with each of these parts in turn, starting with the scheme. As we have already stated, a URL usually begins with a scheme name that identifies the protocol used to access or retrieve the resource to which it refers. Although scheme names are not case sensitive, the convention is to use lower case characters. According to RFC 3986:
" . . . documents that specify schemes must do so with lowercase letters. An implementation should accept uppercase letters as equivalent to lowercase in scheme names (e.g., allow "HTTP" as well as "http") for the sake of robustness but should only produce lowercase scheme names for consistency."
Users, hosts and ports
The authority part of the URL is usually preceded by a double slash ("//"), and is terminated by the next slash character ("/"), a question mark ("?"), a hash character ("#"), or by the end of the URL. We will see examples of how this works in due course. The authority will include a hostname (i.e. a registered domain name or server address), and may optionally include a port number and user information. The authority is defined as follows:
authority = [ userinfo "@" ] host [ ":" port ]
Generally speaking, the port number is not required unless for some reason the URL needs to specify a port number that differs from the protocol's default port number. For example, the hypertext transfer protocol (HTTP) uses port number 80 by default; you do not need to specify the use of port 80 when typing the URL of a web page into your browser's address bar. The following URLs both point to the technologyuk.net home page:
https://www.technologyuk.net:443
https://www.technologyuk.net
Note that in the first example, we specify port number 443. This is the default port number for hypertext transfer protocol secure (HTTPS), and as such does not need to be included in the URL. The second example, which does not specify a port number, will also take us to the technologyuk.net home page (note that if the port number is omitted, the colon that separates it from the host component should also be omitted).
The userinfo component of the authority part of a URL may be required if the right to retrieve or access a particular resource is restricted to a specific user or user group. RFC 3986 has this to say:
"The userinfo subcomponent may consist of a user name and, optionally, scheme-specific information about how to gain authorization to access the resource. The user information, if present, is followed by a commercial at-sign ("@") that delimits it from the host."
A common use of the userinfo component in URLs is for email links like the "Contact" link found at the bottom of each page on this website (see below). Note that mailto: links do not have the double forward slash found in most URLs; this is replaced by the at-sign ("@").
<a href="mailto:webmaster@technologyuk.net">Contact</a>
IP addresses
The host component of a URL, which as we have seen forms part of the authority part, identifies a specific Internet host computer (usually a server of some kind). According to RFC 3986, the host component can take one of three forms:
host = IP-literal / IPv4address / reg-name
The IP-literal option represents a 128-bit IPv6 Internet Protocol (IP) address, enclosed within square brackets (this is the only part of a URL where square brackets may be used). An IPv6 address consists of eight 16-bit pieces, each of which is represented using one to four hexadecimal digits (leading zeros are allowed, but are usually omitted).
The eight 16-bit pieces are presented in order of their significance from left to right. Adjacent pieces are separated by a colon. The last two pieces (i.e. the two least significant pieces) may optionally be presented in IPv4 format using dotted decimal notation (see below).
The representation of IPv6 addresses is shortened as much as possible. For example, the longest sequence of one or more consecutive zero valued 16-bit pieces within an IPv6 address may be elided (represented in a much-shortened form) by removing all of the digits, leaving a pair of consecutive colons. If two such sequences exist within the URL, the left-most sequence is thus encoded.
The following address is the long-hand version of the IPv6 address of the server currently hosting Google's UK website:
[2a00:1450:4005:080b:0000:0000:0000:2003]
If we take out the leading zeros, we get this shortened version:
[2a00:1450:4005:80b:0:0:0:2003]
And if we elide the sequence of empty pieces (there is only one in this example) we get this:
[2a00:1450:4005:80b::2003]
In fact, if you copy and paste the long-hand version into your web browser's address bar, it will automatically shorten the address to match the last version shown above. Don't expect to see the Google UK home page, however. You will reach Google's website, but you will most likely see a page displaying the 404 (page not found) error message, like the one shown below.
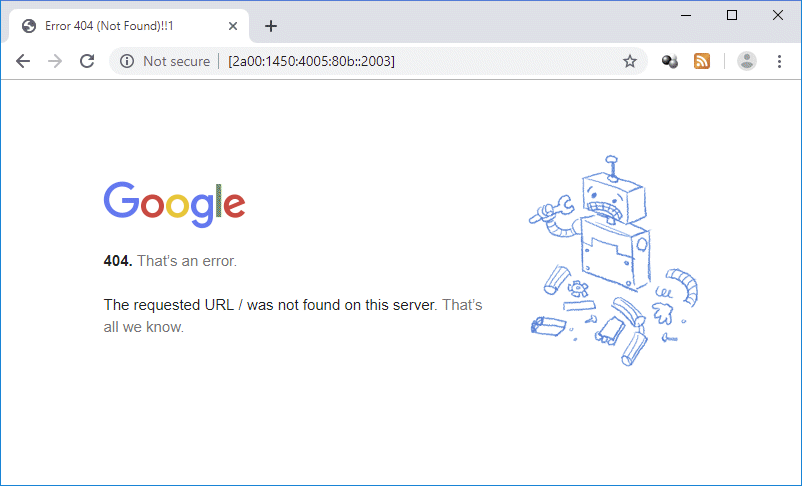
A website's home page cannot usually be accessed using its IP address alone
We should perhaps point out here that the roll-out of IPv6 is ongoing, and that most websites are still using IPv4 addresses. According to an article published on the Internet Society's website on June 6th 2018, Alexa Internet Inc. reported that 17% of the top million websites and 28% of the top thousand websites worldwide had working IPv6 - an increase of 13% and 23% respectively over the previous year.
Regardless of whether or not a website is ready for IPv6, or is still reliant on IPv4 (you can find out here), the likelihood is that its homepage cannot be accessed using an IPv6 or an IPv4 address on its own. This can be for a variety of reasons, the most common being that multiple websites are often hosted on the same server. Additional information is thus required by the server in order to determine which virtual host it should forward the HTTP request to (the subject of virtual hosts will be dealt with elsewhere).
For a host represented by an IPv4 address, the address is presented using dotted decimal notation - a sequence of four decimal numbers in the range 0 to 255, separated by a period ("."). The current IPv4 address for www.technologyuk.net, for example, is 217.160.0.118. If you have a website and you want to find its current IP address, you can use the ping command from within a command line environment, as illustrated below.
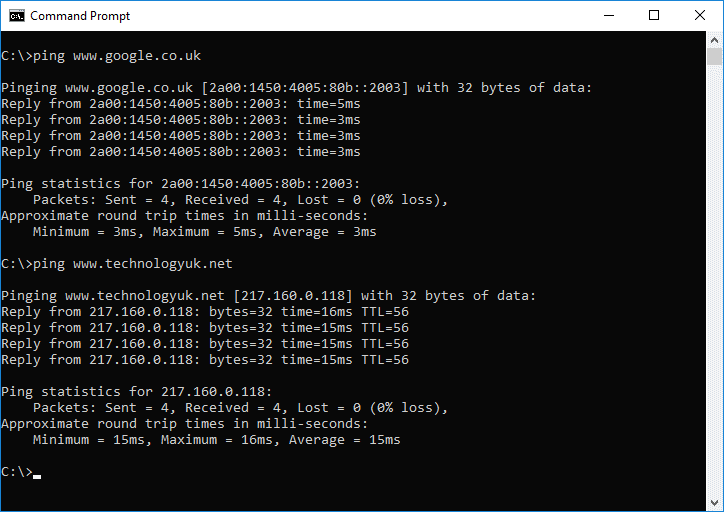
The result of using the "ping" command for (1) www.google.co.uk and (2) www.technologyuk.net
Domain names
For the vast majority of web resources, the URL used to access them will require the host component to be a registered name rather than an IP address. Such a host is described in section 3.2.2. of RFC 3986 as follows:
"A host identified by a registered name is a sequence of characters usually intended for lookup within a locally defined host or service name registry. The most common name registry mechanism is the Domain Name System (DNS). Such a name consists of a sequence of domain labels separated by ".", each domain label starting and ending with an alphanumeric character and possibly also containing "-" characters. The rightmost domain label of a fully qualified domain name in DNS may be followed by a single "." and should be if it is necessary to distinguish between the complete domain name and some local domain."
Wikipedia's definition for "domain name" is as good as any. They describe it as:
" . . .an identification string that defines a realm of administrative autonomy, authority or control within the Internet [that] . . . identifies a network domain, or . . . represents an Internet Protocol (IP) resource, such as a personal computer used to access the Internet, a server computer hosting a web site, or the web site itself or any other service communicated via the Internet."
Web developers and webmasters are primarily interested in the domain names that represent the web sites they develop and maintain. The "administrative autonomy, authority or control" in this context refers to the rights and responsibilities of those charged with creating and maintaining a website.
All registered domain names end with a top-level domain label. Having an established top-level domain label like com at the end of your website's domain name is highly desirable, simply because people have become so familiar with these TLDs. That said, we will see an increasing number of new top-level domains being used because many of the most highly sought-after domain names have already been registered under mainstream TLDs - though not necessarily put to good use.
Many domain names have been registered on a speculative basis and "parked", obviously in the belief that they can be transferred to an interested third party at some later date in exchange for a considerable amount of money. For example, we originally wanted to register this site as either www.technology.com (the existing site has the words "Buy this domain" on its home page) or as www.technology.co.uk ("Domain for sale or lease"). Another alternative would have been www.technology.net (whose current home page is completely blank).
To some extent, the prestige value of having a domain name belonging to one of the long-established TLDs like com or net has been eroded. This is probably due in part to the fact that virtually anybody can register a domain name under one of these TLDs, despite the fact that each was originally intended for a very specific use. The net domain label, for example, was originally intended for domains representing distributed computer networks, but we managed to acquire one for this website!
Perhaps the most glaringly obvious example of a top-level domain label being used for purposes for which it was never intended is the com domain label, which was originally intended for commercial (i.e. for-profit) business organisations. Some years ago, I managed to acquire a com domain for my own (now defunct) personal website. At the time of writing, nearly a third of all registered domain names are com domains, only a relatively small proportion of which are registered to commercial business organisations.
Below the top-level domains, we can have second, third, and even fourth level domains. In fact, a domain name can have as many as 127 domain labels, and each domain label may contain up to 63 characters. Bear in mind, however, that the total length of a domain name must not exceed 253 characters. Other restrictions include domain labels not being allowed to start or end with a hyphen, and top-level domain names not being allowed to consist entirely of numeric characters.
Most registered names will consist of no more than two or three domain labels. This website's registered name, for example, consists of a second level domain label (technologyuk) and a top-level domain label (net).
Some second-level domains are generic, and describe the nature of the enterprise they are intended to represent. In the past, for example companies in the United Kingdom seeking to register a com domain for their website might also seek to register a co.uk domain name, either as a fallback position (in case the com domain name they were seeking is already taken), or to prevent another company or organisation from registering a similar name.
In a co.uk domain name, the top-level domain label is uk (a country code TLD) and the second-level domain label is co, which is the national-level equivalent of the com domain label and is also intended to represent commercial business organisations. As with the com TLD, there are no restrictions on who can register a co.uk domain name. The same is not true for the second-level domain label ac, which is restricted to academic institutions like colleges and universities. The University of Oxford's registered domain name, for example, is www.ox.ac.uk.
Note that both the ac and the co domain labels must be followed by a country code TLD in order for them to be interpreted as second-level domain labels, because they are both also country code TLDs - ac is the country code TLD for Ascension Island, and co is the country code TLD for Colombia.
All domains other than TLDs are sub-domains of the domain immediately above them in the DNS hierarchy. The domain name that appears in a URL is a fully qualified domain name because it contains all of the domain labels that make up the domain name, starting with that of the lowest and ending with that of the top-level domain.
A domain name typically features the name of a company or organisation (e.g. www.microsoft.com), or a term that appeals to a specific interest group (e.g. www.campingdirect.com). Choosing a suitable domain name for your website will go a long way towards giving it a unique identity. It should be easy to remember, and say something about the website so that potential visitors get an idea of what it's all about, even before they arrive at your home page.
Paths
A URL that points to a specific resource on a website must specify the precise location of that resource. In most cases, the resource in question will be a file of some kind. In order to retrieve it, we need to know the name of the file and the directory path that leads to it. If a URL identifies a website but contains no path information, the default document in the website's root directory will be returned (this is usually the website's home page).
The name of the default document in a web directory will depend on the web server configuration. Most Unix or Linux based web servers will use the filename index.html by default, but you might come across variations such as index.htm, default.htm, default.asp, and so on. In fact, the default server configuration will often specify multiple alternative filenames for the default document, as demonstrated by the following code fragment from a typical Apache web server configuration file:
#
# DirectoryIndex: sets the file that Apache will serve if a directory
# is requested.
#
<IfModule dir_module>
DirectoryIndex index.php index.pl index.cgi index.asp index.shtml index.html index.htm \
default.php default.pl default.cgi default.asp default.shtml default.html default.htm \
home.php home.pl home.cgi home.asp home.shtml home.html home.htm
</IfModule>
If the URL does specify a directory path but does not include a filename, the web server will return the default document for the directory or sub-directory to which the path leads. If multiple default document filenames are defined in the web server's configuration file, it searches for a document whose filename matches the first filename in the list. If it cannot find a match, it proceeds to the second filename in the list, and so on. If it goes through the entire list without finding a match, it will return error code 404 (page not found).
Here is an example of a URL that includes a path (highlighted):
http://www.technologyuk.net/mathematics/arithmetic/fractions.shtml
A path consists of a sequence of path segments, separated by a forward slash ("/"). A forward slash also separates the path from the authority part of the URL (i.e. the hostname and any port number or user information that might be present). In the example above, the first two segments tell us how to traverse the website's directory structure from the root directory (mathematics > arithmetic). The final segment is a filename that identifies a specific document within the arithmetic sub-directory (fractions.shtml).
Queries
The query part of a URL - if there is one - directly follows the authority part of the URL, and consists of a question mark ("?") followed by one or more parameters. Queries are often found in URLs used to retrieve dynamic web pages. A dynamic web page is a page generated in response to information sent to a web server by a browser.
A URL containing a query is created every time you use a search engine, or type a search term directly into your browser's address bar. The illustration below shows the page that was returned when we typed the term "uniform resource locator" directly into the address bar of Mozilla Firefox and hit ENTER.
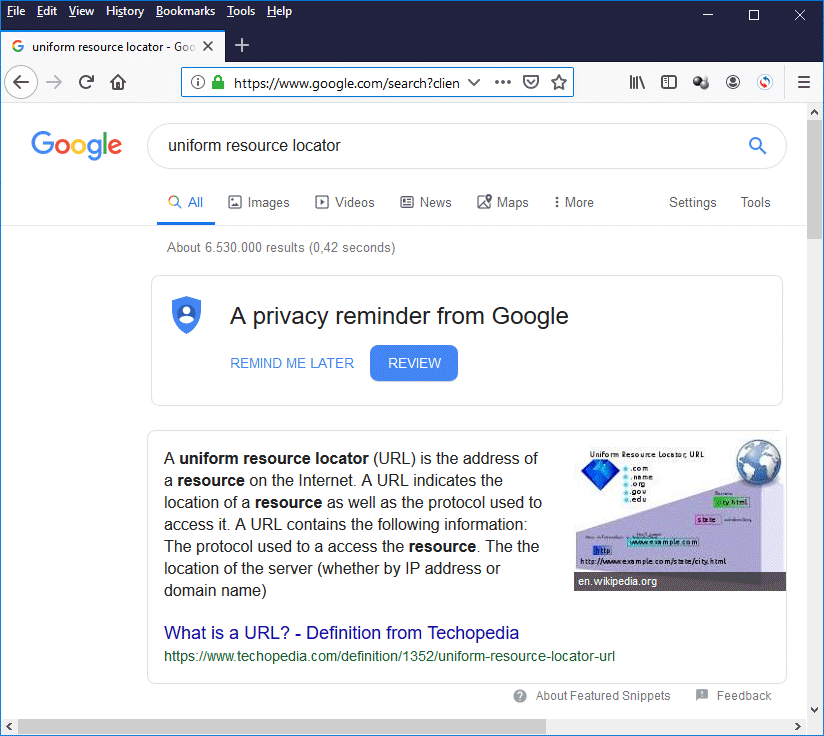
The result of searching for "uniform resource locator" in Firefox
You can't see the complete URL in the illustration, but we have reproduced it below:
https://www.google.com/search?client=firefox-b-d&q=uniform+resource+locator
The authority part of the URL points to Google's website because we have Google set as the default search engine for Firefox. We have highlighted the query part of the URL (this is usually referred to as the query string). Parameters usually take the form of key-value pairs separated by a delimiter - in the case, the ampersand character ("&").
The query string in our example contains two parameters. The first parameter (firefox-b-d) identifies the client browser as Firefox. We think the b-d part indicates that the search request is being sent from outside the United StatesS. The second parameter contains the search term itself (uniform+resource+locator).
A query string can be quite long. There is, in fact, no official limit on how long a query string can be. The URL created by Firefox when we carry out exactly the same search using the search facility on Google's home page looks like this:
https://www.google.com/search?source=hp&ei=J6VSXfSRKIPUwQKLmYuoCg&q=uniform+resource+locator&oq=uniform+resource+locator&gs_l=psy-ab.3..0l10.2162.2162..4755...0.0..0.46.87.2......0....2j1..gws-wiz.l57OUi0xENQ&ved=0ahUKEwi0wcGE5f_jAhUDalAKHYvMAqUQ4dUDCAc&uact=5
This time, the search term itself (which for some reason is included twice) is just one of several parameters. The remaining parameters are all rather strange-looking alpha-numeric character sequences that are obviously not meant for human consumption.
Fragments
Most URLs point either to a website or to a specific document on a website. Occasionally, however, a URL will point to a location within a document. A URL of this kind will include a fragment part consisting of a fragment identifier that references that location.
The location pointed to by a fragment identifier is usually an HTML element inside a web page whose id attribute is set to a specific value. The fragment identifier consists of the hash symbol ("#"), followed by the value assigned to the target element's id attribute.
The following URL points to the section "Common browser features" in the page entitled "Web Browsers" in this section.
http://www.technologyuk.net/website-development/world-wide-web/web-browsers.shtml#ID07
If you copy and paste this URL into a browser's address bar and hit ENTER, it will take you directly to the section header for the "Common browser features" section.
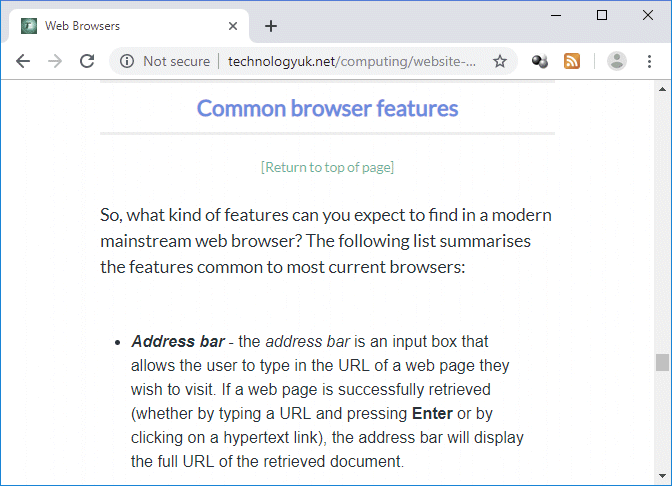
The "Common browser features" section of the page "Web Browsers"
Here is the HTML code that sets up the section header as a target (usually referred to as an internal page link, or bookmark) for the fragment identifier in the URL:
<h2 id="ID07">
Common browser features
</h2>
Fragment identifiers can be very useful if we want to create a link to a specific section of a very long document. They can also be used to create a table of contents within a long document, enabling users to navigate to various parts of the document from the table of contents (and back again) in a single click, rather than having to scroll endlessly up and down within the document.